Claude Fable 5(フェイブル5)のスペック早見表:1M(100万)コンテキスト・128K出力・$10/$50価格を一気に把握

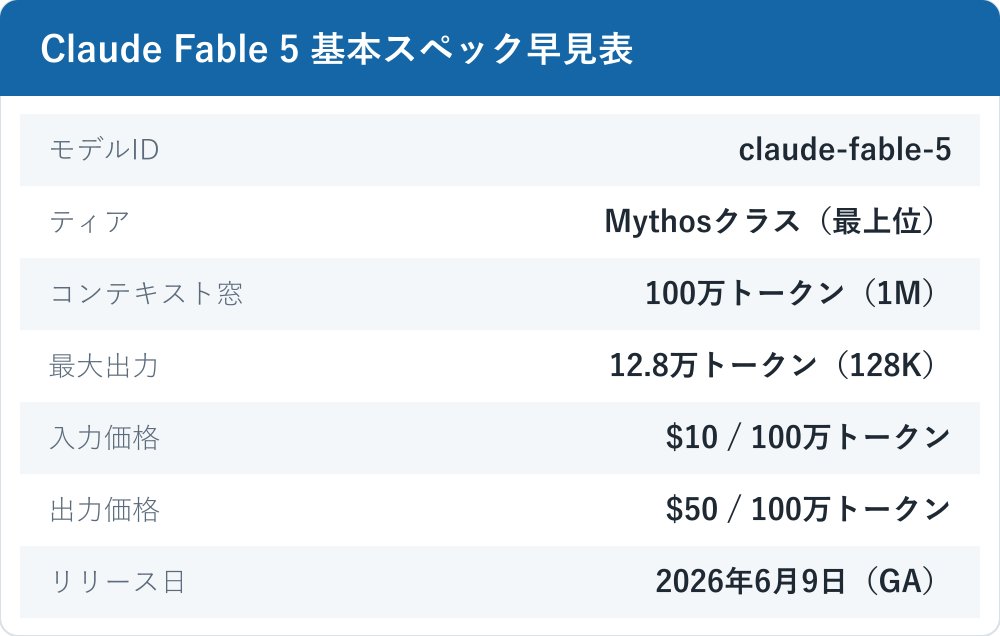
Claude Fable 5(フェイブル5)は、2026年6月9日に一般提供が始まったAnthropicの新しい最上位モデルです。モデルIDは claude-fable-5。Opus/Sonnet/Haikuの上に新設された「Mythosクラス」に属し、Anthropicは「最も高性能・最も賢いモデル」と位置づけています。
この記事は、Fable 5のコンテキスト窓・最大出力・価格・トークナイザといった「数字」を、表と図でまとめた仕様リファレンスです。100万(1M)コンテキスト/128K出力/入力$10・出力$50という主要スペックを、迷わず引けるように整理しました。
機能の使い勝手やベンチマークの細部よりも、まず「設定する側が押さえるべき値」を一覧化することを目的としています。API実装やコスト試算の前に、ここで全体像をつかんでおくと判断が速くなります。
- Fable 5の基本スペック(コンテキスト窓・最大出力・モデルID)の数値
- 入力$10/出力$50という価格と、キャッシュ・Batchでの割引率
- Opus 4.7由来のトークナイザと、トークン消費が増える注意点
- thinking・effortなどAPI設定で間違えやすいポイント
Fable 5の基本スペック早見表
まずは全体像です。Fable 5は既定で100万トークンのコンテキストウィンドウに対応し、1リクエストあたり最大128Kトークンまで出力できます。この1Mは「長文向けの別料金ティア」ではなく、標準価格の範囲内で使える既定値である点が特徴です。
モデルIDと位置づけ
モデルIDは claude-fable-5 です。Fable 5は一般提供されるMythosクラスのモデルで、能力面ではOpusクラスより上に置かれています。姉妹モデルの Claude Mythos 5(claude-mythos-5)は、選別されたサイバー防御者・インフラ事業者向けに「Project Glasswing」を通じた限定提供のみで、一般には公開されません。同じ基盤モデルでも、Mythos 5は一部領域で安全分類器(セーフガード)を外した構成という違いがあります。
コンテキスト窓と最大出力
コンテキスト窓は100万トークン、最大出力は128Kトークンです。これはOpus 4.8と同じ枠組みで、長い設計書やコードベース全体を一度に渡すような使い方を想定しています。なお最大出力を大きく取る場合は、HTTPタイムアウトを避けるためにストリーミング前提で実装するのが安全です。Claudeの料金や枠の考え方はClaudeのプラン別料金を調べた記事もあわせて参照すると整理しやすくなります。
リリース日と提供チャネル
Fable 5は2026年6月9日に一般提供(GA)が開始されました。ローンチ日の時点で、Claude API・claude.ai(有料サブスク向け、6月22日頃までの段階的展開)・Claude Code・AWS Bedrock・Google Vertex AI・Microsoft Foundry・GitHub Copilotで利用できるようになっています。無料ティアでは提供されません。
価格とコストの早見表
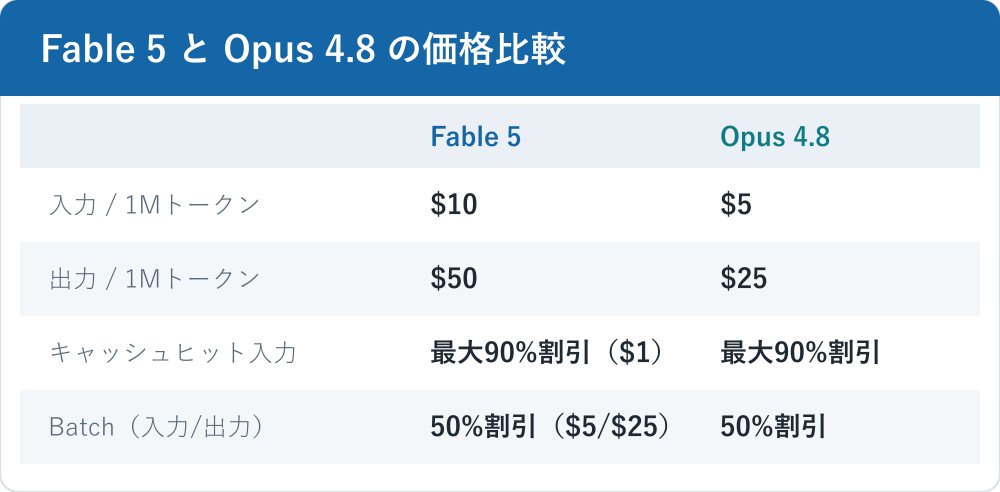
Fable 5の価格は、入力が100万トークンあたり$10、出力が100万トークンあたり$50です。これはOpus 4.8($5/$25)のちょうど2倍にあたります。割引の仕組みも合わせて押さえておくと、実際のコスト感をつかみやすくなります。
キャッシュとBatchの割引
プロンプトキャッシュのキャッシュヒットでは、入力が最大90%割引($1/MTok)になります。Batch APIを使う場合は、入力・出力ともに50%割引($5/$25)です。繰り返し同じ前置きを送るワークフローや、レイテンシをそこまで気にしないバッチ処理では、この割引が効くかどうかで実コストが大きく変わります。Claude全体の課金体系についてはClaudeの料金体系を調べた記事で基礎を確認しておくと比較しやすいはずです。
価格は「入力$10/出力$50」が基準値です。キャッシュヒットで入力が最大90%、Batchで入力・出力とも50%下がる、という2段構えで覚えておくと、見積もりのときに迷いにくくなります。
トークン多消費というコスト要因
価格表だけ見ると「Opus 4.8の2倍」で済む話に見えますが、後述するトークナイザの違いにより、同じテキストでも消費トークンが増えます。つまり「1トークンあたりの単価が2倍」かつ「必要トークン数も増えがち」という二重の効きになり得ます。海外の開発者コミュニティでも、実効的なタスクコストがOpus 4.8の数倍に達し得るという指摘が出ています(最悪ケース寄りの見方で、一発で成功する確率の高さが価格差を相殺するという反対意見もあります)。
トークナイザとトークン消費の注意点
Fable 5とMythos 5は、Opus 4.7で導入されたトークナイザを使用します。これにより、同じテキストでもOpus 4.7以前のモデルより約30%多くトークンを消費します(ワークロード依存の概算値です)。価格と並んで、コスト試算で見落としやすいポイントです。
なぜトークン数が増えるのか
トークナイザはテキストをトークンに分割する仕組みで、モデルごとに異なります。Opus 4.7世代のトークナイザは分割の粒度が変わっており、結果として同じ入力でもカウントが増える傾向があります。日本語や記号・コードを多く含む入力では、増え方がさらに変わることもあります。実装時は推測で見積もらず、トークンカウントの仕組みで実数を確認するのが堅実です。
トークン数の確認方法
正確なトークン数は、利用するモデルIDを指定してカウント用のエンドポイントで測るのが確実です。OpenAI系のトークナイザ(tiktokenなど)はClaude向けには合わないため、Fable 5のコストを見積もるなら必ずFable 5自身を指定して数えます。max_tokensやキャッシュの発火閾値も、このトークン数を基準に調整します。
thinking・effortのAPI設定早見
Fable 5のAPIの作法は、Opus 4.8/4.7とほぼ同一です。ただし思考モードまわりに、Fable 5固有のクセが1つあります。設定を間違えると400エラーで弾かれるため、ここは順に押さえておくと安全です。
思考モードはアダプティブのみ
Fable 5の思考モードは「アダプティブシンキング」のみに対応します。手動の budget_tokens は廃止され、thinking: {type: "adaptive"} を使います。固有のクセとして、thinkingを明示的に「無効化」({type: "disabled"})すると400エラーになります。Opus 4.8/4.7では無効化が許容されるのに対し、Fable 5では thinking パラメータ自体を省略する必要があります。thinking機能の考え方そのものはClaudeのthinking機能を調べた記事でも触れています。
サンプリングパラメータも廃止
temperature/top_p/top_k を既定値以外に設定すると、Fable 5でも400エラーになります。これはOpus 4.7/4.8から引き継がれた制限です。出力の方向づけは、これらのパラメータではなくプロンプトや次のeffortで調整します。
effortパラメータの段階
思考の深さと全体のトークン消費は、effort パラメータで制御します。low/medium/high/xhigh/max の段階があり、Fable 5では max と xhigh も利用できます。コーディングやエージェント用途では高めの設定が向き、コストを抑えたいときは下げる、という調整が基本です。budget_tokensの代わりに使う制御、という位置づけで覚えておくとよいでしょう。
設定で弾かれやすい3点。(1)budget_tokensは使わずadaptiveにする、(2)thinkingを明示的にdisabledにせず省略する、(3)temperature等のサンプリング指定を外す。この3つを守れば、Fable 5の基本リクエストは通ります。
対応機能とデータ保持ポリシー
スペックの数字だけでなく、運用面の前提も早見表に入れておくと判断がぶれません。とくにデータ保持ポリシーは、用途によっては設計判断に直結します。
ローンチ時点の対応機能
Fable 5はローンチ時点で、effortパラメータ、Task Budgets(ベータ)、memory tool、context editing経由のtool-resultクリア(ベータ)、サーバー側コンパクション、高解像度ビジョン、構造化出力、Web検索の動的フィルタリングに対応しています。エージェント的な長時間タスクや、長文コンテキストの圧縮を伴う処理を想定した機能が揃っています。
安全分類器とフォールバック
Fable 5は安全分類器を搭載し、サイバーセキュリティ・生物/化学・蒸留に関するリクエストをOpus 4.8へ回します。拒否(refusal)は stop_reason が refusal のHTTP 200として返り、出力前の拒否であれば課金されません。オプトインのベータ機能 fallbacks パラメータを使えば、別モデルでの再実行も指定できます。Anthropicの早期データでは、Opus 4.8へのフォールバックが起きるのは平均でセッションの5%未満で、95%超はFable 5上で完結するとされています(第三者監査値ではない点に注意してください)。
30日のデータ保持ポリシー
Mythosクラス(Fable 5を含む)のトラフィックは、ゼロデータ保持ではなく30日間のデータ保持ポリシーが適用されます。ファーストパーティ・サードパーティの両面で適用され、既存のZDR契約をこのモデルクラスに限って上書きします(Opus 4.8/Sonnet 4.5/Haiku 4.5はZDRのままです)。金融・医療・セキュリティ用途では、この点を事前に確認しておく必要があります。
他モデルとの位置づけ早見
Fable 5は新ティアの最上位モデルで、能力面の評価も高めに報告されています。ただし、ここで挙げる数値はいずれもベンダー報告またはアグリゲータ値であり、独立した第三者監査ではない点を前提に読む必要があります。

コーディング・知識作業の傾向
SWE-bench Verifiedのリーダーボードでは、Fable 5が95.0%で1位、Opus 4.8の88.6%を上回ったと報告されています。SWE-bench Pro(エージェント型コーディング)でも、Fable 5が80.3%、Opus 4.8が69.2%、GPT-5.5が58.6%、Gemini 3.1 Proが54.2%という値が出ています。知識作業を評価するGDPval-AAでは、Fable 5/Mythos 5が1932で首位、Opus 4.8が1890と続きます。コーディングと知識作業の軸でFable 5が上位という構図は複数ソースで一致していますが、いずれもベンダー/アグリゲータ報告です。
ビジョンと実利用事例
ビジョン系のGDP.pdf(ツールなし)タスクでは、Fable 5が29.8%で首位、GPT-5.5が24.9%、Opus 4.8が22.5%と報告され、Anthropicはビジョンタスクの新たな最先端と位置づけています。実利用の事例としては、Stripeが約5000万行のRubyコードベース全体の移行を1日で完了したという報告もありますが、これは顧客の自己申告であり第三者検証はありません。なお、未確認の数値(一部のベンチや事実性スコアなど)については、現時点で公式の確定的な公表がないため、本記事では断定していません。公式の一次情報は、Claude APIのドキュメント、Anthropicの公式発表、価格はClaude APIの料金ページで確認できます。
まとめ
Fable 5は、1M(100万)コンテキスト・128K出力・入力$10/出力$50という、覚えやすい主要スペックを持つ新ティアの最上位モデルです。価格はOpus 4.8の2倍で、さらにOpus 4.7由来のトークナイザにより消費トークンが約30%増えやすい、という2点がコスト判断の中心になります。
早見表として押さえる要点
運用で先に確認すべきは、(1)思考はadaptive固定でdisabled明示は不可、(2)サンプリング指定は外す、(3)effortで深さとコストを調整、という設定面の3点です。加えて、Mythosクラスは30日のデータ保持ポリシーが適用される点も、用途によっては設計判断に効いてきます。スペックの数字と運用前提をセットで把握しておけば、Fable 5を採用するかどうかの判断材料が一通り揃います。最新の仕様変更は公式の更新情報で追うのが確実なので、運用前には公式ドキュメントの該当ページを直接確認しておくと安心です。




