Claude Fable 5(フェイブル5)ベンチマーク総ざらい:SWE-bench Verified 95.0%・GDPval-AA 1932 でGPT-5.5・Gemini 3.1 Proを上回る

2026年6月9日に一般提供が始まったClaude Fable 5(フェイブル5)は、Anthropicが「最も高性能・最も賢い」と位置づける新ティアのモデルです。Opus / Sonnet / Haiku の上に新設された「Mythos クラス」に属し、コーディング・知識作業・ビジョンの主要ベンチマークで GPT-5.5(ジーピーティー5.5) と Gemini 3.1 Pro(ジェミニ3.1プロ) を上回ったと報告されています。
この記事では、SWE-bench Verified / Pro、GDPval-AA、GDP.pdf ビジョンといった数値を競合と並べて整理します。ただし、これらはいずれもベンダー(Anthropic)またはアグリゲータの報告値であり、独立した第三者監査ではない点を最初に明記しておきます。読む側として、その前提を持ったうえで数字を眺めるのが正確な向き合い方です。
また、一部で出回った FrontierCode Diamond の数値や AA-Omniscience のハルシネーション率には誤帰属・反証があるため、この記事ではそれらの数値は扱いません。確認できた範囲の事実だけを並べます。
- Fable 5 のスペック(コンテキスト100万トークン・出力12.8万トークン・料金$10/$50)の早見
- SWE-bench Verified / Pro での Fable 5・Opus 4.8・GPT-5.5・Gemini 3.1 Pro の比較
- GDPval-AA と GDP.pdf ビジョンの Elo・正答率比較
- ベンチ数値の「読み方」と、書かない(反証済み)数値の整理
Claude Fable 5 とは何か:新ティア「Mythos クラス」の位置づけ
Opus の上に立つ最上位モデル
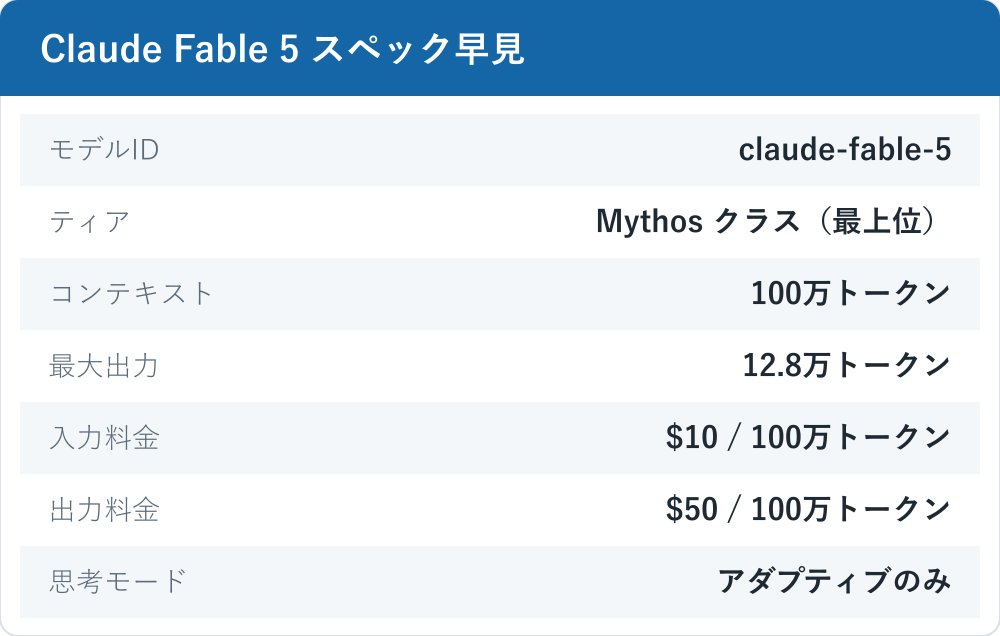
Claude Fable 5 のモデルIDは claude-fable-5 です。従来の Opus / Sonnet / Haiku という3段構成の上に「Mythos クラス」という新ティアが設けられ、Fable 5 はその一般提供版にあたります。Anthropic は Fable 5 を自社で最も高性能・最も賢いモデルと表現しており、能力面では Opus クラスより上に位置づけられます。姉妹モデルの Claude Mythos 5(claude-mythos-5)も同時発表されましたが、こちらは Project Glasswing を通じた限定提供のみで、一般には提供されません。
スペックの基本:100万トークンと/
Fable 5 は既定で100万(1M)トークンのコンテキストウィンドウに対応し、1リクエストあたり最大12.8万(128K)トークンの出力に対応します。この1M は標準価格内の既定値で、別料金ティアではありません。料金は入力100万トークンあたり$10、出力100万トークンあたり$50で、これは Opus 4.8($5/$25)のちょうど2倍です。プロンプトキャッシュのキャッシュヒットでは入力が最大90%割引($1/MTok)、Batch API では入力・出力とも50%割引になります。価格や階層の考え方を整理したいときは、Claudeの料金体系をまとめた記事もあわせて参照すると把握しやすくなります。
API の作法:思考モードと禁止パラメータ
Fable 5 の思考はアダプティブシンキングのみです。手動の budget_tokens は削除され、代わりに effort パラメータ(low/medium/high/xhigh/max)で制御します。注意したいクセとして、thinking を明示的に「無効化」する指定(thinking:{type:’disabled’})を送ると400エラーを返す点があります。temperature / top_p / top_k も既定値以外に設定すると400エラーになります。API の基本作法は Opus 4.8 / 4.7 とほぼ同一で、思考の挙動を整理したい場合はClaudeのthinking機能の解説も手がかりになります。
SWE-bench で見るコーディング性能
SWE-bench Verified:95.0%で首位
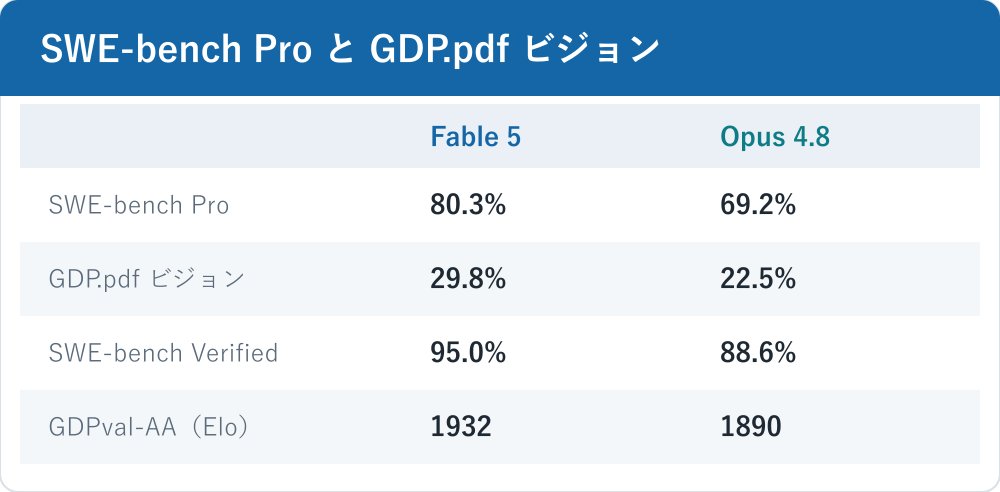
SWE-bench Verified のリーダーボードで、Fable 5 は95.0%を記録して1位となりました。Opus 4.8 の88.6%を上回る数値で、Mythos Preview は93.9%とされています。SWE-bench Verified は、実在するソフトウェアの課題(GitHub の Issue 修正など)を人手で検証したセットで、コーディングエージェントの実力を測る代表的な指標として広く参照されます。95.0%という水準は、検証済み課題のほとんどを解けることを意味し、コーディング領域での到達点の高さを示します。
SWE-bench Pro:エージェント型での差
より難度の高い SWE-bench Pro(エージェント型コーディング)では、ベンダー報告値で Fable 5 が80.3%、Opus 4.8 が69.2%、GPT-5.5 が58.6%、Gemini 3.1 Pro が54.2%です。Verified より絶対値は下がりますが、ここでも Fable 5 と他モデルの差は明確に出ています。特に GPT-5.5・Gemini 3.1 Pro との開きは20ポイント以上あり、エージェントとして自律的にコードを書き進めるタスクで差がつく構図が読み取れます。GitHub Copilot でも Fable 5 が一般提供されているため、実務の開発フローへ組み込みやすい点も合わせて押さえておきたいところです。
数値を読むときの注意点
SWE-bench 系の数値は、Verified が複数ソース(リーダーボード+Anthropic)で確認できる一方、Pro / GDP.pdf などは二次ソースに依拠しています。数値自体は複数ソースで一致しているものの、Anthropic 公式のベンチ表が画像提供であるため、厳密には「複数ソースが一致して報告している値」という性格です。コーディング用途で Claude を運用する際の前提知識は、Claudeの最新アップデート情報の記事でも継続的に追えます。
知識作業ベンチ GDPval-AA:Elo 1932 でトップ

GDPval-AA とは
GDPval-AA は、Artificial Analysis が運営する Elo 型の実務知識作業評価です。経済的に価値のある実務タスクをどれだけうまくこなせるかを、対戦形式のレーティングで測ります。SWE-bench のような正答率ではなく Elo スコアで表されるため、モデル間の相対的な強さを比較するのに向いています。
競合との比較
このベンチで Fable 5 / Mythos 5 は1932を記録して1位です。Opus 4.8 は1890、GPT-5.5 は1769、Gemini 3.1 Pro は1314となっています。Fable 5 と Opus 4.8 の差は42ポイントで僅差ですが、GPT-5.5 とは160ポイント以上、Gemini 3.1 Pro とは600ポイント以上の開きがあります。Elo は差が大きいほど勝率の差が大きいことを意味するため、知識作業の領域で Fable 5 が頭一つ抜けている構図が読み取れます。
Elo レーティングは「絶対点」ではなく「相対的な勝ちやすさ」を示す指標です。点差100は理論上およそ勝率64%に相当するとされ、点差が大きいほど対戦での優劣が安定して出ます。GDPval-AA の数値はあくまで Artificial Analysis の運営する評価上の値である点に留意してください。
分析・金融ベンチでの補足
Anthropic は、Fable 5 が自社のコア分析ベンチマーク(Hex 作)で初めて90%を突破し、Hebbia のシニアレベル Finance Benchmark で全モデル中最高スコアを記録したと報告しています。Hex も自社評価で Fable 5 を90%超と独立に裏付けています。ただし Hebbia の最高スコアは「Anthropic がそう報告した」形でのみ確認されており、独立検証済みと断定はできません。事例として、Stripe が約5000万行の Ruby コードベース全体の移行を1日で完了したと報告していますが、これは顧客の自己申告であり第三者検証はない点も合わせて押さえておきましょう。
ビジョン性能 GDP.pdf:新たな最先端
GDP.pdf(ツール無し)での首位
GDP.pdf(ビジョン/ツール無し)タスクで、Fable 5 は29.8%で首位に立ちました。GPT-5.5 が24.9%、Opus 4.8 が22.5%、Gemini 3.1 Pro が16.7%です。Anthropic は Fable 5 をビジョンタスクの新たな最先端(SOTA)モデルと表現しています。絶対値こそ3割弱とまだ難度の高いタスクであることがうかがえますが、競合との相対差は明確で、PDF や画像を理解しながら回答する用途で優位に立つ構図です。
3軸での総合的な構図
ここまでの SWE-bench Pro(コーディング)、GDPval-AA(知識作業)、GDP.pdf(ビジョン)の3軸を通して見ると、Fable 5 が GPT-5.5 と Gemini 3.1 Pro をリードする構図は複数ソースで一致しています。ただし繰り返しになりますが、すべてベンダー/アグリゲータ報告であり、独立第三者監査ではありません。3軸そろってリードという点は心強い材料ですが、用途ごとに実際のワークロードで検証する姿勢が現実的です。
書かない数値:反証・誤帰属の整理
比較に使わなかった数値も明示しておきます。第一に、FrontierCode Diamond で Fable 5 が29.3%という主張は反証されました。一次情報では Diamond の最高は Opus 4.8 の13.4%で、Fable 5 の FrontierCode Diamond スコアは現時点で未検証のため、この記事では数値を出しません。第二に、「Claude ファミリーが AA-Omniscience で36.18%のハルシネーション率」という記述は誤りで、36.18%は Opus 4.7 単体の値です。Fable 5 自体の AA-Omniscience ハルシネーション率は公開ソースで未確認のため、事実性スコアは断定しません。
ベンチ比較表とスペック早見
主要ベンチの一覧
ここまでの数値を一覧にまとめます。いずれもベンダー/アグリゲータ報告値である点を前提に読んでください。
| ベンチマーク | Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 95.0% | 88.6% | ― | ― |
| SWE-bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
| GDPval-AA(Elo) | 1932 | 1890 | 1769 | 1314 |
| GDP.pdf ビジョン | 29.8% | 22.5% | 24.9% | 16.7% |
SWE-bench Verified の GPT-5.5・Gemini 3.1 Pro の値は今回の根拠範囲で確認できていないため、表では「―」としています。確認できた値だけを並べる方針です。
料金・スペック早見
運用判断のためのスペックも整理しておきます。Fable 5 の料金は入力$10・出力$50で、Opus 4.8($5/$25)のちょうど2倍に設定されています。コスト面でよく話題になる「約30%のトークン増」は、比較対象に注意が必要な数字です。Fable 5 と Mythos 5 は Opus 4.7 で導入されたトークナイザを使うため、同じテキストでトークン消費が約30%増えるのは Opus 4.7 より前のモデルと比べた場合に限られます(ワークロード依存の概算値)。同じトークナイザを引き継ぐ Opus 4.8 との比較では、この約30%増は当てはまりません。料金の総額感をプラン単位でつかみたい場合は、Claudeのプラン別料金の解説も判断材料になります。
無料利用ウィンドウとデータ保持
Fable 5 は6月9日から6月22日まで、Pro / Max / Team / シート制 Enterprise プランに追加費用なしで含まれます。6月23日以降はこれらのプランから外れ、使用クレジット(課金)が必要になります(容量次第で延長の可能性ありと注記)。なお Mythos クラス(Fable 5 を含む)のトラフィックには、ゼロデータ保持ではなく30日間のデータ保持ポリシーが適用され、既存のZDR契約をこのモデルクラスに限り上書きします。金融・医療・セキュリティ用途では要確認です。
提供チャネルと運用上の注意
どこで使えるか
ローンチ日に Fable 5 は、Claude API、claude.ai(有料サブスク向け、6月22日頃までの段階的展開)、Claude Code、AWS Bedrock、Google Vertex AI、Microsoft Foundry、GitHub Copilot で一般提供となりました。無料ティアでは提供されません。提供面の広さから、既存の開発・業務フローへ組み込みやすい設計です。
安全分類器とフォールバック
Fable 5 は安全分類器を搭載し、サイバーセキュリティ・生物/化学・蒸留に関するリクエストを Opus 4.8 へ回します。拒否は stop_reason refusal を持つ HTTP 200 として返り、出力前の拒否なら課金されません。Anthropic の早期データでは、Opus 4.8 への安全フォールバックが発生するのは平均でセッションの5%未満で、95%超のセッションはフォールバックなしに Fable 5 上で完結するとされています(第三者監査値ではありません)。なお、公開された不満として安全フィルタの過剰反応(良性タスクの誤ブロック)が指摘されており、Anthropic も誤検知の存在を認め、ローンチ後に調整すると表明しています。
コストとルーティングの考え方
実務面の中心的な論点はコストです。Fable 5 は一般提供される Anthropic モデルの中で最も高価で、トークン多消費により実効タスクコストが Opus 4.8 の3〜5倍になり得るとの指摘があります(最悪ケース・確度中で、一発成功率の高さで2倍プレミアムが相殺されるとの反対意見もあります)。実運用では「難題は Fable 5、それ以外は Opus 4.8」というルーティングが現実的な落としどころとして語られています。最新情報を追う記事と合わせて、用途別の使い分けを設計していくのが堅実です。なお一次情報はAnthropicの公式発表、API仕様はClaude API Docs、GDPval-AA の集計はArtificial Analysisで確認できます。
まとめ
Claude Fable 5 は、SWE-bench Verified 95.0%・SWE-bench Pro 80.3%・GDPval-AA 1932・GDP.pdf 29.8% という数値で、コーディング・知識作業・ビジョンの3軸で GPT-5.5 と Gemini 3.1 Pro を上回ったと報告されています。ただしこれらはすべてベンダー/アグリゲータ報告で、独立第三者監査ではありません。
数値の前提を忘れない
3軸そろって首位という構図は複数ソースで一致しており、Fable 5 の能力の高さを示す材料としては有力です。一方で、Anthropic の公式ベンチ表が画像提供であること、SWE-bench Pro / GDP.pdf 等が二次ソース依拠であること、FrontierCode Diamond と AA-Omniscience の数値が反証/誤帰属であることは、数字を語るうえで欠かせない注釈です。
用途で判断する
料金が Opus 4.8 の2倍という条件下では、すべてを Fable 5 に寄せるより「難題は Fable 5、それ以外は Opus 4.8」という使い分けが現実的です。なお約30%のトークン増は Opus 4.7 より前のモデルと比べた場合の概算であり、トークナイザを共有する Opus 4.8 との比較で生じる差ではありません。無料ウィンドウ(6月9日〜22日、容量次第で延長可能性あり)の間に、自分のワークロードで実際の費用対効果を測っておくと、6月23日以降の課金移行後も無理のない運用設計につながります。ベンチ数値は出発点として有用ですが、最終判断は手元のタスクでの検証に委ねるのが堅実です。




